Web_Crawler
Changelog
9/3/2025: Khởi tạo bài viết Ghi chú về Web Crawler
12/3/2025: Bổ sung một số công cụ Crawler khác
Web crawler (hay còn gọi là web spider, bot, hoặc crawler) là một chương trình hoặc phần mềm tự động được thiết kế để duyệt qua các trang web trên internet, thu thập thông tin và lập chỉ mục dữ liệu từ các trang đó. Web crawler hoạt động bằng cách truy cập một trang web, đọc nội dung, tìm các liên kết (link) trên trang, sau đó tiếp tục truy cập các liên kết đó để khám phá thêm các trang khác. Quá trình này thường được thực hiện một cách có hệ thống và liên tục.
Mục đích của Web Crawler
- Công cụ tìm kiếm: Các crawler như Googlebot (của Google) thu thập dữ liệu từ hàng tỷ trang web để lập chỉ mục, giúp người dùng tìm kiếm thông tin dễ dàng.
- Thu thập dữ liệu (Web Scraping): Lấy thông tin cụ thể như giá sản phẩm, bài viết, hoặc dữ liệu nghiên cứu.
- Giám sát web: Kiểm tra cập nhật nội dung, phát hiện lỗi liên kết, hoặc theo dõi thay đổi trên các trang.
- Phân tích dữ liệu: Thu thập dữ liệu lớn (big data) để phân tích xu hướng, thị trường, hoặc hành vi người dùng.
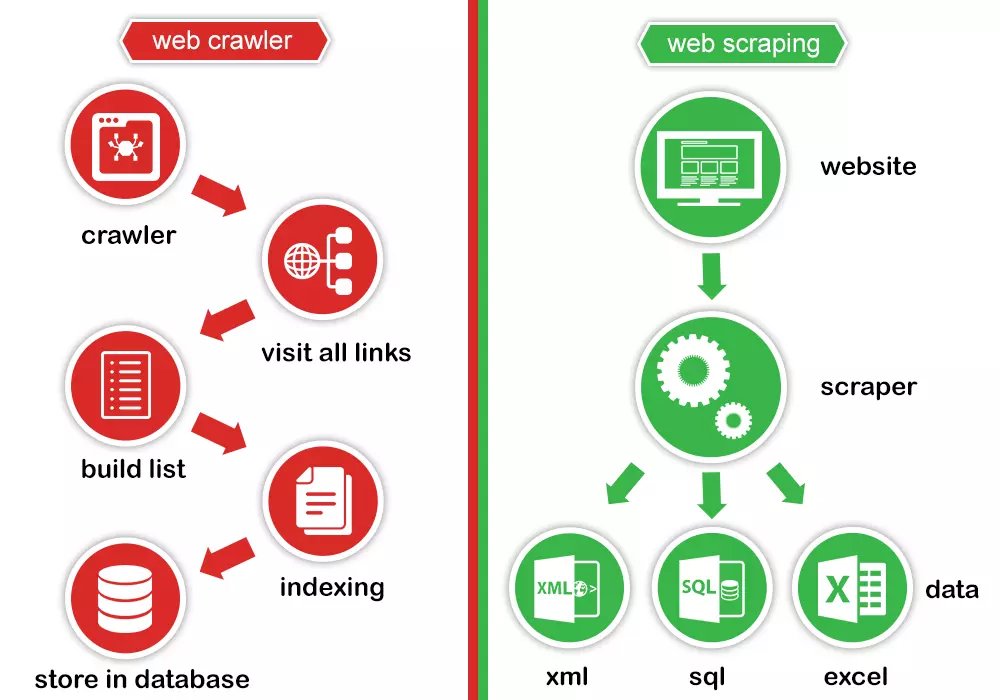
So sánh giữa Web Crawling và Web Scraping

Công cụ Firecrawl
- Đây là một công cụ mã nguồn mở, có thể vào cả việc crawl và scraping.
- Theo tài liệu thì công cụ này có thể selft-hosted hoặc đăng ký sử dụng free API (bị giới hạn crawl khoảng 500 trang web và một số tính năng khác).
- Tính năng nổi bật của Firecrawl:
- Xử lý nội dung động: Nếu website dùng JavaScript (ví dụ: SPA - Single Page Application), Firecrawl tự động render và lấy dữ liệu
- Đầu ra sạch: Dữ liệu được loại bỏ quảng cáo, menu, footer
- Crawl tự động: Chỉ cần đưa URL gốc, Firecrawl sẽ tự tìm và crawl tất cả subpages mà không cần sitemap.
Xác định nhu cầu khi sử dụng Firecrawl
Muốn crawl toàn bộ website hay chỉ scrape một vài trang ?
-
Crawl: Lấy toàn bộ nội dung từ một domain (ví dụ: tất cả bài viết trên một blog).
-
Scrape: Lấy dữ liệu cụ thể từ một hoặc vài trang (ví dụ: giá sản phẩm từ trang chi tiết).
Dữ liệu đầu ra cần định dạng gì ?
-
Markdown: Phù hợp để dùng trực tiếp cho LLM (cho việc huấn luyện AI).
-
JSON: Dữ liệu có cấu trúc (structured data) như danh sách sản phẩm, bài viết, v.v.
Cập nhật: 12/3/2025
AI Web Scraper: Thunderbit
- Tham khảo video: Cào Mọi Thông Tin trên Website chỉ 2 Click bằng AI - Không code - Thunderbit
- công cụ này mình có thể cài đặt, hoặc add thêm extension cho Chrome.
- Mình xem video thì thấy công cụ này khá hay, dùng cho những người không chuyên quá nhiều về kỹ thuật.
- Xem pricing thì bản free chỉ cho phép cào tối đa 6 trang web trong tháng.
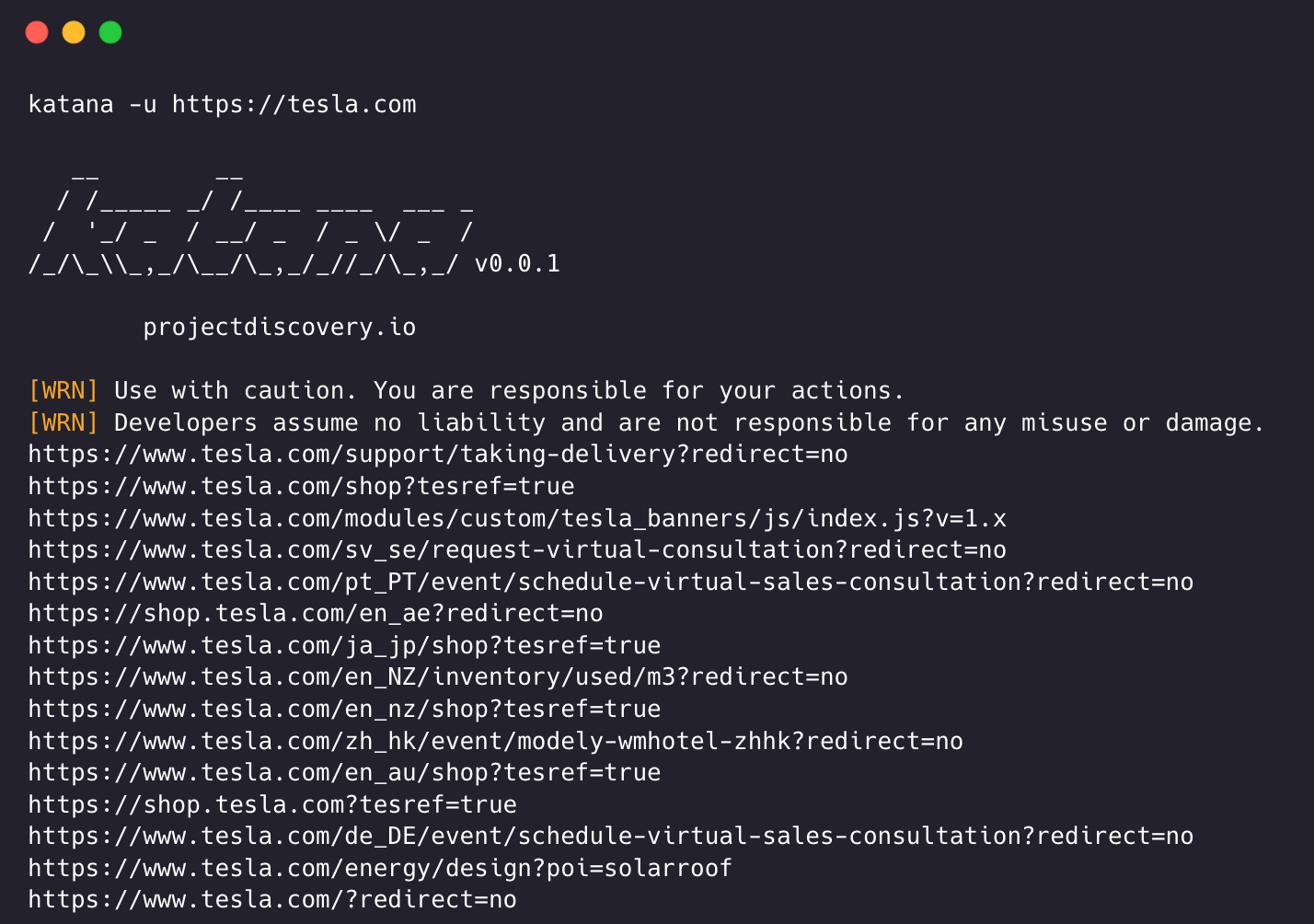
Katana
A next-generation crawling and spidering framework.